Courses: Introduction to GoldSim:
Unit 11 - Dealing with Dates and Time
Lesson 3 - Referencing Dates and Times Using Run Properties
Now that we have discussed how to set up a calendar-based simulation, how do we take advantage of this? As we saw in the previous Lesson, the x-axis is for time histories is labeled in terms of the date instead of elapsed time in calendar-based simulations.
But the real power of calendar-based simulations is the ability to directly reference dates (and time of day) during a simulation. What do we mean by this and why would you want to do it? Let’s consider three simple examples:
- You are simulating a business that only operates during certain hours of the day (e.g., 8AM to 5PM) Monday through Friday;
- You are simulating a pump that withdraws water from a lake at a specified constant rate, but never operates during July and August (i.e., during these two months, the pumping rate is zero);
- You are simulating a machine that undergoes preventive maintenance on January 15 and July 15 of each year.
In each of these cases, to represent this in the model, we need a way to directly reference the month, day of week, day of month and/or time of day. GoldSim tracks these, and at any point in the simulation knows their values, but how do we explicitly reference these items?
You should recall from a previous Lesson (Unit 6, Lesson 9) that GoldSim provides a number of special reserved names, referred to as Run Properties, that can be directly referenced in expressions. You can enter the names of the Run Properties directly when creating expressions (just as you would enter the name of an output), or you can insert them into an expression using the Insert Link dialog.
We noted that one of the most common Run Properties is ETime (elapsed time), and we used this Run Property in a previous Exercise. But there are many other Run Properties that we have not yet discussed. In order to see this, in a new model create an Expression element. After doing so, right-click in the Equation field and select Insert Link… from the menu. The following dialog will be displayed:
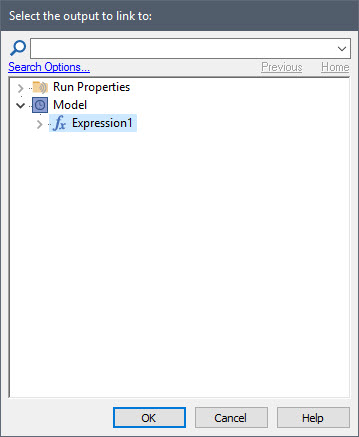
As we noted before, at the top of the dialog is a folder labeled “Run Properties”. If you expand this folder, you will see that the Run Properties are organized into four categories (Calendar Time, Elapsed Time, Simulation and Reporting Periods):
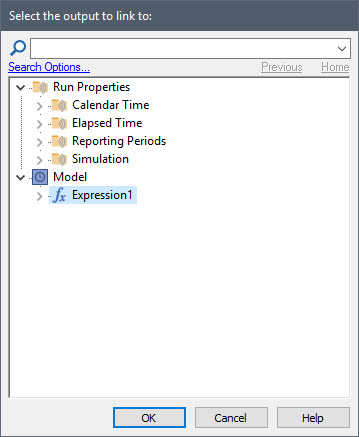
Expanding any particular category folder lists all of the Run Properties in that category. When we first introduced Run Properties, we looked at the Elapsed Time category. Now we want to look at the Calendar Time category:
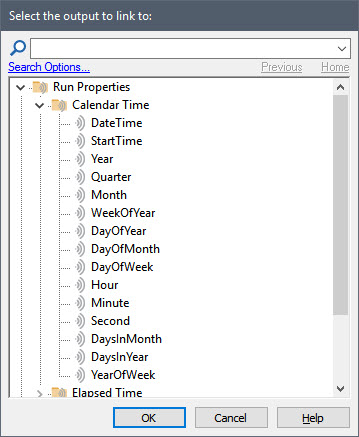
You can see that there are a number of properties we can reference.
For the purposes of the three examples above, we would need to reference Month, DayOfMonth, DayOfWeek and Hour. Let’s revisit those three examples:
- To simulate a business that only operates during certain hours of the day (e.g., 8AM to 5PM) Monday through Friday, we would probably create a Conditional Expression (perhaps named Business_Open) that looked like this:
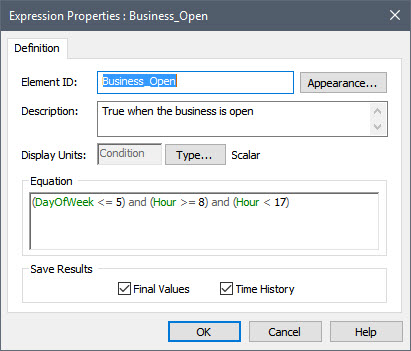
This is an Expression element which is defined as a condition (conditions were introduced in Unit 5, Lesson 3 and discussed further in Unit 6, Lesson 10). In order for this to work, however, we need to know what GoldSim considers to be the first day of the week (DayOfWeek=1). In this example, Monday is assumed to be the first day of the week. It turns out, however, that this is actually an option that you can specify via the Advanced Time Settings dialog accessed by pressing the Advanced… button in the Time tab of the Simulation Settings dialog: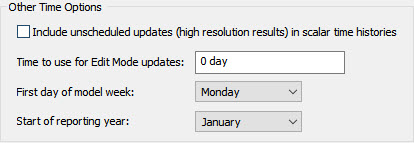
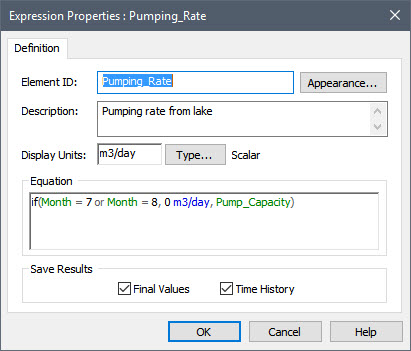
- To simulate a pump that withdrawals water from a lake at a specified constant rate, but never operates during July and August (i.e., during these two months, the pumping rate is zero), you would define the pumping rate as follows:
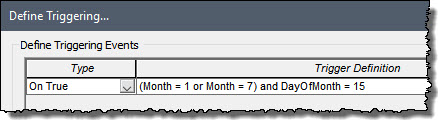
- Simulating a machine that undergoes preventive maintenance on January 15 and July 15 of each year is a bit different than the two examples we discussed above. Why? Because in this case, we want to “trigger” something to occur at a specific time or date (as opposed to set a condition to true or false during certain time periods). Being able to do something like this is quite important for many types of systems, and we will discuss this type of modeling in great detail in Unit 14. For now, it is sufficient to note that GoldSim provides the ability to create a “trigger” to do things like this. In this example, we want to trigger a preventive maintenance when the following condition becomes true:
In the next Lesson, we will work through an Exercise where you can practice using the Calendar Time Run Properties yourself.
Before leaving this Lesson, however, it is worthwhile to point out a common source of confusion when first starting to create calendar-based models that reference Run Properties. As discussed above, GoldSim provides a Run Property called “Month” that can be referenced in expressions. It is a dimensionless integer from 1 and 12, and represents the current simulated month of the year. GoldSim also provides a unit called “mon”. These should not be confused! They are two different things. The former is a Run Property that can be referenced in expressions; the latter is a unit that can be assigned to values. Similarly, GoldSim provides a Run Property called “Year” that can be referenced in expressions. It is a dimensionless integer that represents the current simulated calendar year (e.g., 2017). GoldSim also provides a unit called “yr”. Again, they are two different things. The former is a Run Property that can be referenced in expressions; the latter is a unit that can be assigned to values.