Courses: Introduction to GoldSim:
Unit 11 - Dealing with Dates and Time
Lesson 2 - Creating Calendar-Based Models
As we have already seen (Unit 6, Lesson 4), timestepping options are defined using the Simulation Settings dialog. You can open the simulation settings dialog by pressing F2, choosing Run | Simulation Settings from the main menu bar, or by pressing Simulation Settings button in the toolbar:

Open the dialog now so we can examine it:
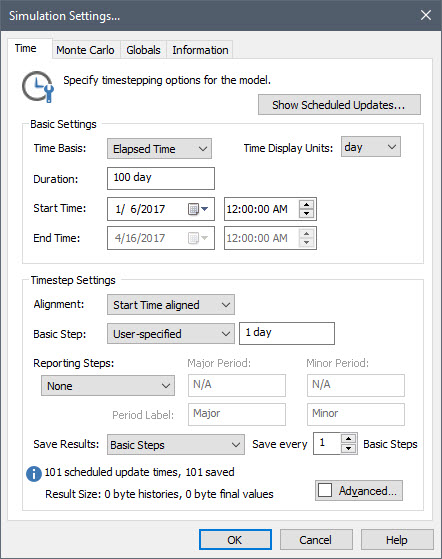
By default, the Time Basis is set to “Elapsed Time”. To create a calendar-based model, we must change this to “Calendar Time”. When you do so, the dialog will look like this:
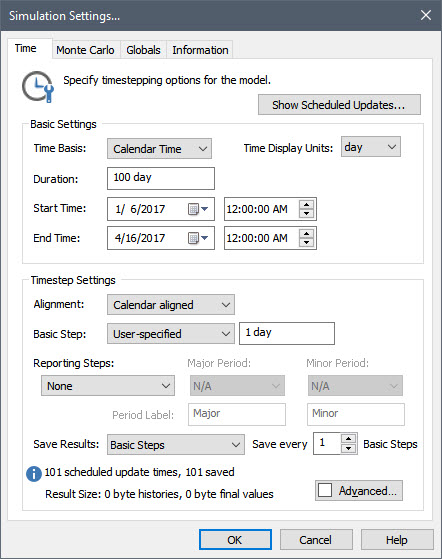
The key point to notice here is that you specify a Start Time and an End Time (in terms of calendar date and time of day).
Note: The format in which dates are displayed in GoldSim is determined by the Windows settings for your machine. To change these settings (e.g., to display dates in European format with the day before the month), go to Control Panel and edit the Regional Options. Also, note that when editing a date, if you select the drop-down list next to the date it will be clear which date is specified.
The Start Time defaults to the time the file was created. To get more comfortable with this dialog, change the End Time now (e.g., increment the month by 1). If you do this, you will note that the Duration is automatically updated:
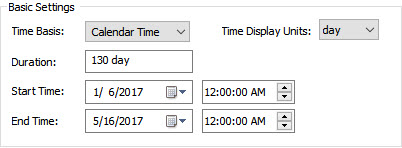
Note: If you edit the Duration directly, it will adjust the End Time accordingly (after leaving the Duration field or pressing OK).
Now let’s look at the options for the Basic Step. The default is “User-specified” (in which you can enter any time period), but for a Calendar Time model, other calendar-based options are available:
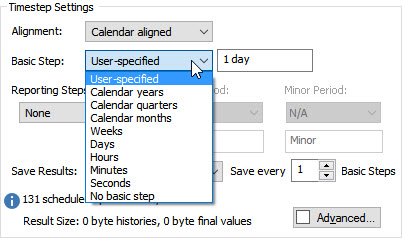
Weeks, Days, Hours, Minutes and Seconds are easy to understand, and if you select one of these, you can then choose the number of each of these periods to use per timestep:
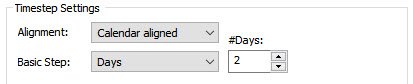
In this example, there would be a 2-day timestep.
Note: The Basic Step does not need to divide evenly into the Duration. If it does not, the final step is simply adjusted (shortened) accordingly.
Calendar Years, Quarters and Months are specified similarly, but if you use one of these there is an important impact on your model: the Basic Step will not be constant. This is because the length of a month, quarter and year is not constant (different months, and hence different quarters, have different lengths, and due to leap years, the length of a year also changes).
To see this, let’s make some edits. Set the Start Time to 1/1/2018 and the End Time to 1/1/2021 (make sure that the time for both is set to 12 AM). Then set the Basic Step to “Calendar months”. The dialog should look like this:
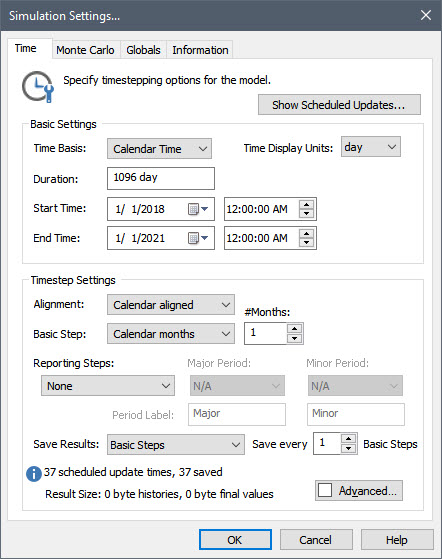
Now press Show Scheduled Updates… As discussed previously (Unit 7, Lesson 4), when you do so, GoldSim will display a list of the scheduled updates:
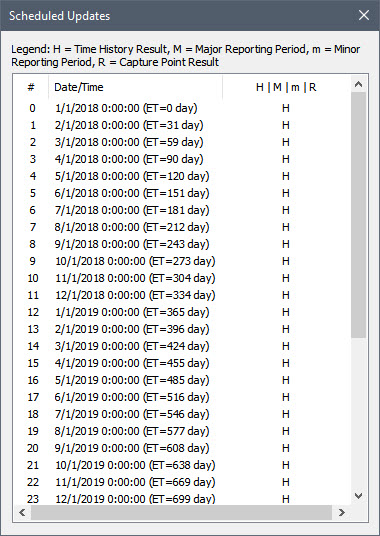
You can see that an update occurs on the first of each month. For each update, the elapsed time in the simulation (ET) is also listed. Obviously, the timestep length will vary throughout the simulation (i.e., from 28 to 31 days).
What if you wanted each update to occur on the 15th of the month? To do so, you would need to make two changes:
- Change the Start Time to 15 January 2018; and
- Change the Alignment to “Start Time aligned”.
If you do so, and press Show Scheduled Updates… again, you will see that the updates now fall on the 15th of each month.
So you can see that we have lots of flexibility with Calendar Time simulations to specify calendar-based timesteps. But how does such timestepping affect models and how can we take advantage of it?
The most obvious impact we will see is how time histories are plotted. To see this, let’s open a model we built in a previous Exercise. You should have saved a model named Exercise7.gsm. Open the model now. (If you failed to save that model, you can find the Exercise, named Exercise7_Evaporating_Pond.gsm, in the “Exercises” subfolder of the “Basic GoldSim Course” folder you should have downloaded and unzipped to your Desktop.)
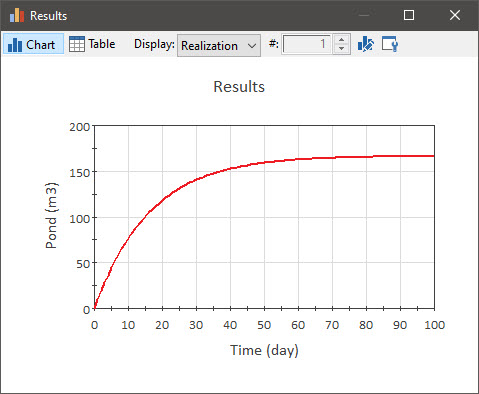
If we run this model, and plot the time history of the Pond volume, it looks like this:
Return to Edit Mode and open the Simulation Settings dialog. Let’s change this model to a Calendar Time model, changing the Start Time to 1 January 2025 and the End Time to 11 April 2025:
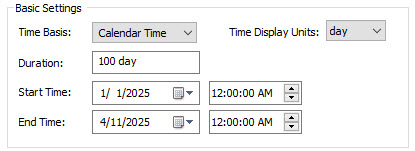
Note that the simulation still runs for 100 days. Run the model now and view the time history again. It looks like this:
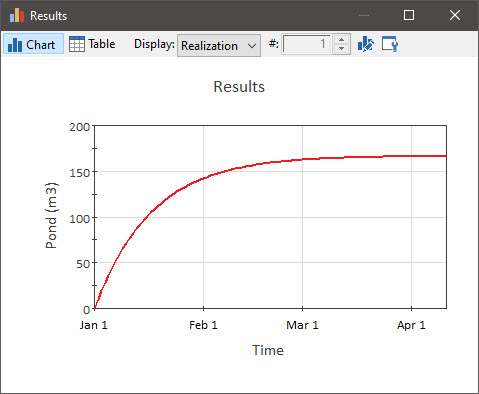
You can see that the x-axis is now labeled in terms of the date instead of elapsed time.
This is just the most obvious impact of running a calendar-based simulation, and there are a number of powerful ways we can take advantage of these kinds of simulations. We will discuss several of these features in more detail later in this Unit.
Before leaving this Lesson, however, it is important to discuss one other issue related to calendar-based simulations that it is important to understand. GoldSim provides a number of units to represent time (e.g., day, sec, hr). Units in GoldSim must, of course, have a fixed definition, and as mentioned previously (Unit 5, Lesson 4), this definition can be viewed by opening the GoldSim Units Manager (by selecting Model|Units… from the main menu):
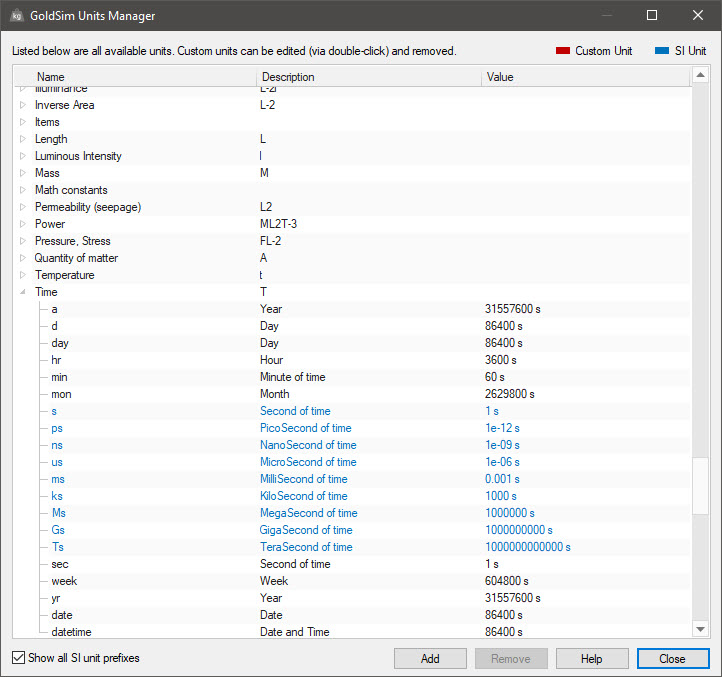
From the screen above, for example, we can see that the definition of a day is 86400 seconds.
One of the time units that GoldSim provides is “mon” (month). So you could, for example, define a rainfall rate as 3 mm/mon. However, it is very strongly recommended that you never do this. Why? Because someone could interpret this (when running a calendar-based simulation) to mean that 3 mm will fall in January, 3 mm will fall in February, and so on. This would imply that the rainfall rate was changing (since January has more days than February, it would imply that the rate of rainfall in February was higher). In order to do this, however, the definition of the unit “mon” would need to change every month! Of course it cannot do this. The definition of the unit remains constant. The unit “mon”, like all units, has a very specific (and constant) definition: 1 mon is equal to 30.4375 days. Basically, it is the average length of a month (365.25 days/12). So 3 mm/mon would be interpreted by GoldSim as 3 mm/30.4375 days = 0.09856 mm/day.
So as a general rule, when running calendar-based simulations, you should avoid using the unit “mon” when defining inputs. (The unit “yr” has a similar problem: its actual definition is 365.25 days in GoldSim). Using either of these units could lead to confusion.